
AI Well-Aging Company
AI
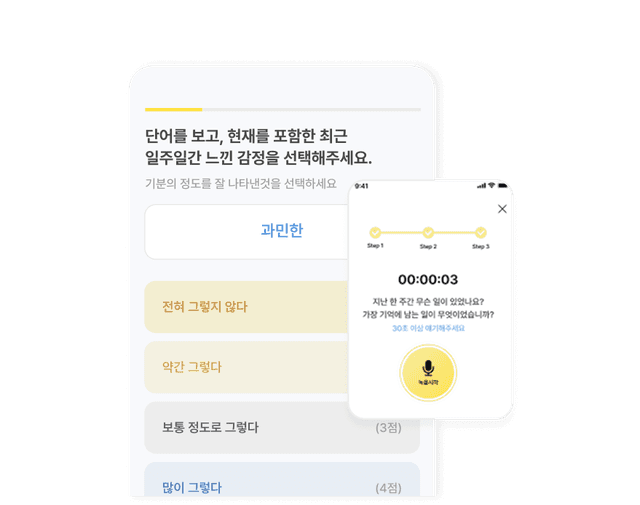
비전,사운드,텍스트를 통합한
딥테크 멀티모달 AI
단일 AI 모델만으로는 웰에이징에 필요한 헬스케어 서비스 전반을 구현할 수 없습니다. 컴플렉시온은 SCI급 논문과 공인 시험성적서로 검증된 자체 개발 AI 모델을 기반으로, 웰에이징에 특화된 초격차 멀티모달 콘텐츠를 제공합니다.
COMPLEXION x Multimodal AI

VISION
컴퓨터 비전 AI를 통해 유저의 행동 패턴과 자세를 분석합니다

SOUND
유저의 사운드 속성을 인공지능으로 분석하여 증상을 파악하고 분류합니다

TEXT
패시브 데이터, 대화 데이터를 TEXT로 변환하여 건강 요소를 표준화합니다
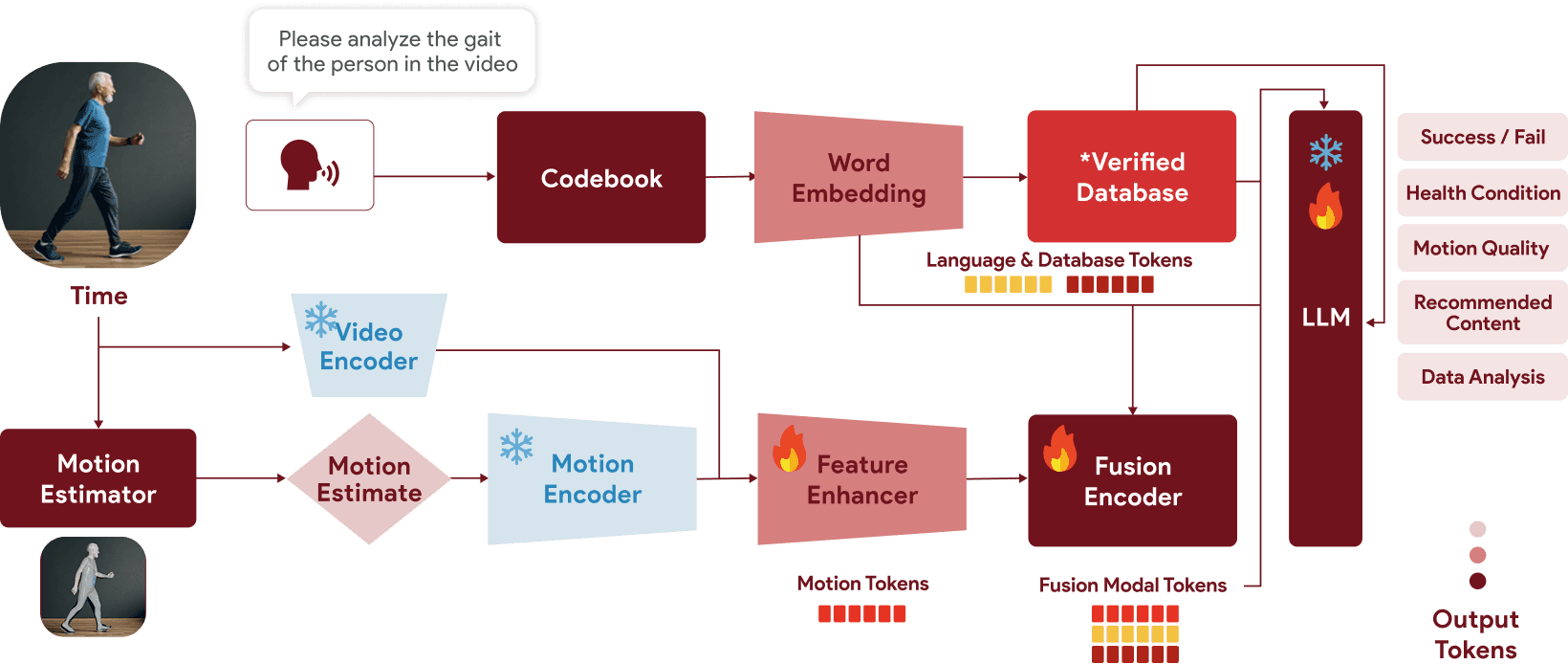
COMPLEXION's Multimodal AI
컴플렉시온의 멀티모달 AI 모델은 Vision(영상)·Sound(음성)·Text(LLM)를 통합 분석하여
사용자 개별 상태와 목적에 정확히 맞춘 맞춤형 피드백을 생성합니다.
특히 기존 단일모달 AI 대비 2.79배 높은 사용자 선호도가 검증되었습니다.
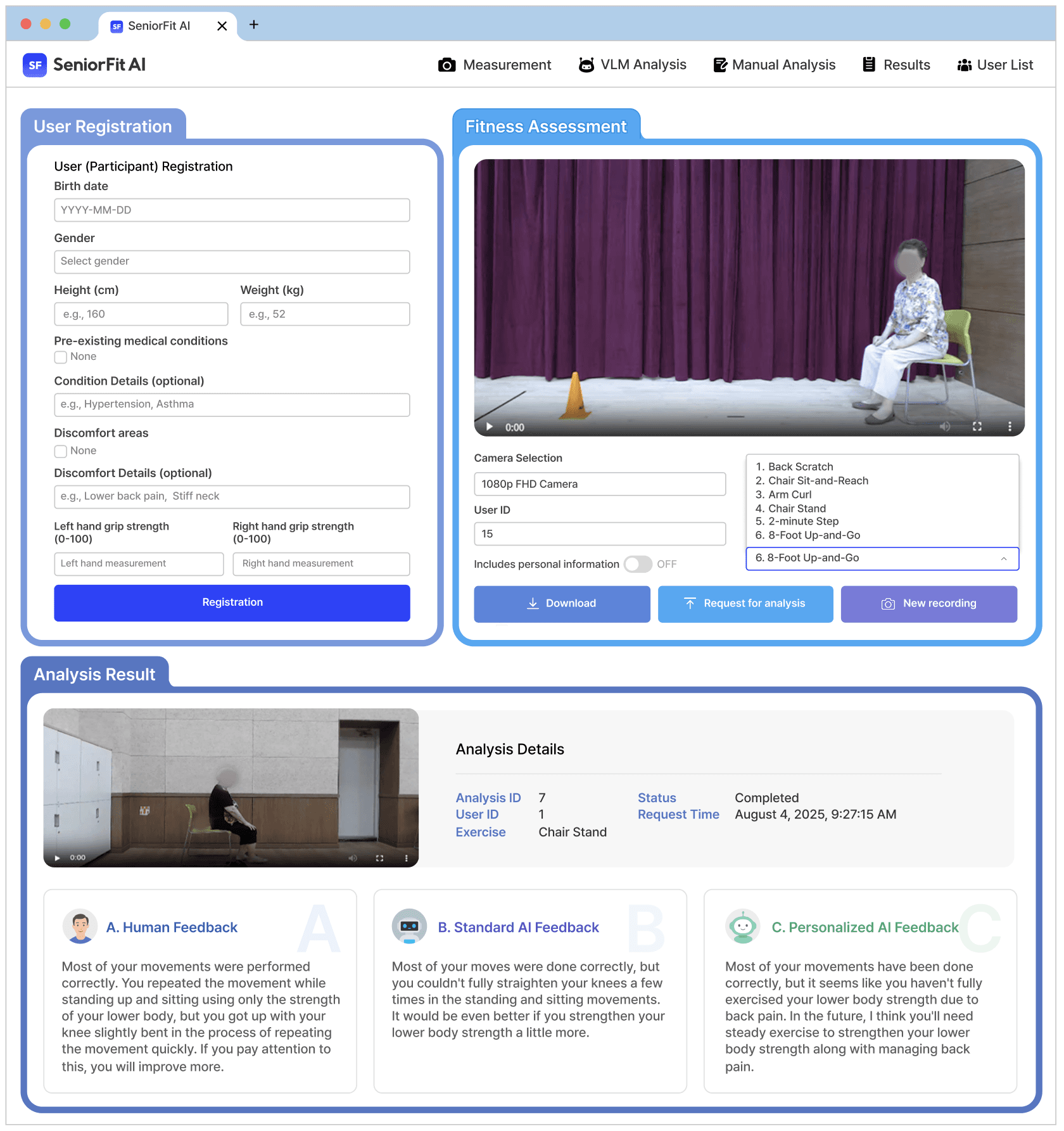
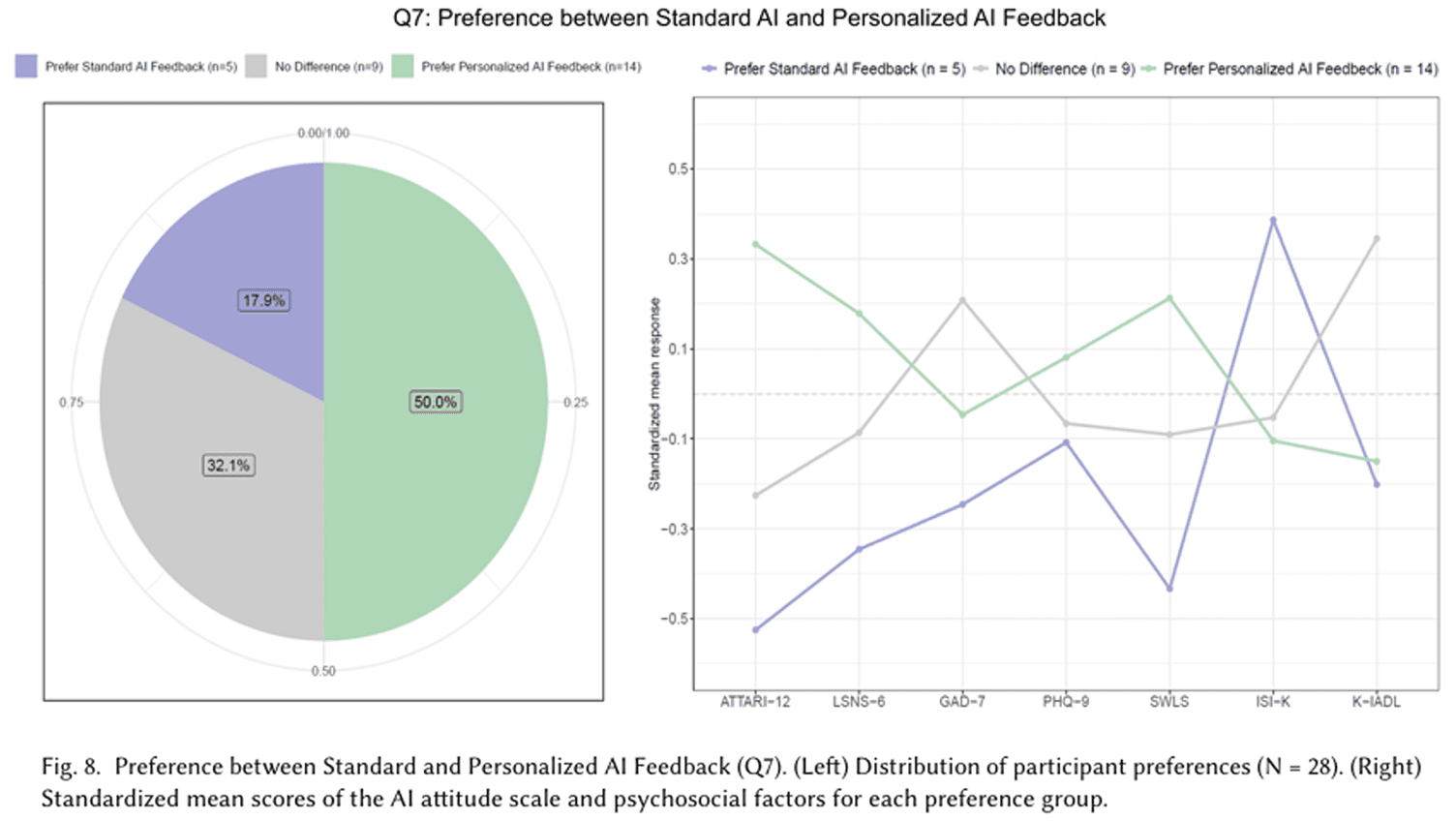
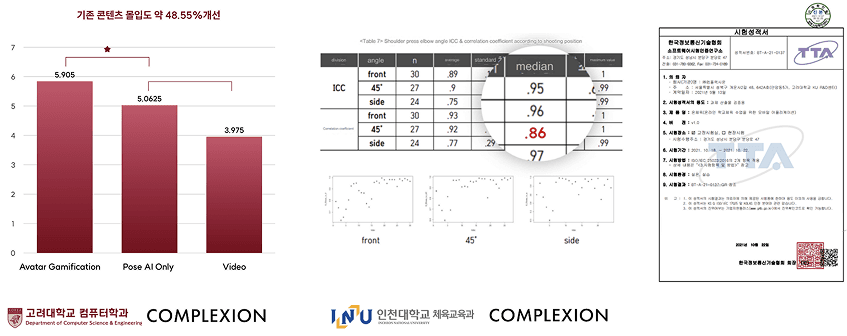
산학 공동연구로 검증된 사용자 경험과 기능성
컴플렉시온의 AI 기술은 기능적 정확도뿐 아니라 사용자 경험(UX)까지 완성도를 높이기 위해 총 8회 이상의 공식 산학 공동연구를 통해 검증을 완료했습니다.
SCI급 논문 발표 1
생성형 AI 기반 기법을 통해 기존 장애인 신체 결손 인식률을 약 70%에서 90%로, 총 20%p 향상시켰습니다.
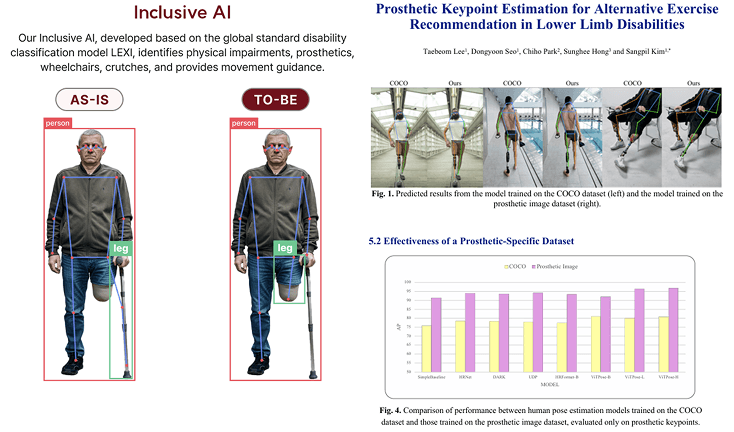
SCI급 논문 발표 2
사람 얼굴이 거의 식별되지 않을 정도로 흐릿하거나 깨지거나, 노이즈가 심하게 낀 최악의 환경에서도 얼굴인식 정확도를 최대 +22.97%p 향상 (기존 대비 96.2% 정확도)시켰습니다.
